How often should we update our Gentoo?
There is no absolute correct answer for that. Gentoo is just like other distros2, s**t does happen when do update. No matter what species of penguins you pet, they all might get sick and updating interval is not really relevant. However, you should never wait for a year even just a few months, though your version might still be supported. Believe me, that's not wise. Gentoo is a rolling release, it doesn't imply you must update often or when you must do the update, not like those 6-month update cycle distro. But if you wait up for months, you might encounter many trouble to get your Gentoo updated. I have seen probably a couple of forums posts asking how they can update after years without using the computers, they were all advised to start a freah install of latest version.
Since I started to use eix, eix-diff told me the changes on Portage tree. I used to update daily, but I didn't do that anymore. Because it's very often only a few packages would get updated. I am now using a weekly update method and I have been doing this for more than a month.
Here is the steps I do:
- Running
sudo eix-syncto update Portage tree, read the diff.- See what packages get removed, you might have few removed, see if there are replacements.
- See what packages get added, play with them.
- Running
emerge -pvuDt worldto see what can be upgraded.-tshows you the dependency, it's very helpful to understand why a package is pulled into update list. Remember only those packages rendered in bold text are in your world file/var/lib/portage/world. world file contains packages which you specifically toldemergeto install without using-1aka--oneshotoption.- Also pay attention to package list at top level (leftmost at output of
emerge -t) which are not rendered in bold text, they belong to the system set packages. As what system sounds, you should try to make them up to date. - You might have some blocked packages, if you can't resolve, search on forums.
- If you are informed there are news using
eselect newsto read, make you you read them.
- It's not necessary to update all packages. I usually update packages has updated on minor version number, but that's just me. Besides that, I read logs using
emerge -pvul <package>to see if I really want to update. You should also pay attention on USE flags, some might be removed, added, or switched between default-on/off. - When I have a list to update, I would run
emerge -quD1to update.-1to make sure you don't put packages into your world file. By the way, I recently found out you can doemerge -pvuD world | sudo genlop -p1 to get a estimated merge time. - After update, make sure you read all messages. You can also find them at
/var/log/portage/elog.- Do what they tell you, if it tells you to run a program, then run it.
- If there is configuration files update, then run
dispatch-confto update your configuration files and don't just pressuto use new configuration file, you might be overriding what changes you have made. - If you want to check last merge time, you can run
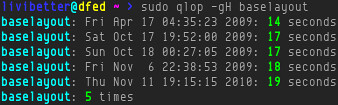
sudo genlop -tl --date 1 day agoit should give you updates in last one day. Or I have written a short script to check the result of last merge.
- Running
revdep-build.
There are some packages might require you to update partial or even entire system, meaning all packages. For instance, GCC, but it's not always as I updated from 4.4.3-r2 to 4.4.4-r2. You can rebuild all of course, but be honest, do you really know what improvement has been made in that update and how much improvement of performance you can get by re-compiling with newer version of GCC? Don't waste energy since your system is running well for you.
So, when do you need to do such mass rebuild? When emerge tells you to do so. I only did full system rebuild once when I updated GCC, I think it's when I installed 4.4.3-r2 to new slot. There is another case you might need to do mass rebuild if you change USE flag in /etc/make.conf. But it's still not necessary, you can wait for packages to get new version, then use emerge -pvuDNt <package> to do update, so you won't have to rebuild just for new USE flag. I removed nls a while ago, many packages are not merged with nls, I still have 46 are still with nls. There is one more case, the X window and its drivers. Some didn't read the message and they posted why keyboard, mouse, video didn't work after updated.
Gentoo has some guides about upgrade, e.g. GCC and Kernel. When you have doubts or you are nervous about an update, do a search for those guides. Or wait for a little bit, say a few days, then search on forums to see if there is any victims :) Also bug reports might be helpful, search package on Gentoo Packages, there is a Bugs link, which can lead you to bug list of that package.
Trying not to use unstable packages or hardmask packages, I currently only has one package in /etc/portage/package.keyword. Those packages usually bring other unstable packages in. It's not like they are seriously unstable, but doing so you might need to be more careful. I actually had been living with those for quite a long time, I believe I had ever had probably 50 packages in keywords and a couple in unmask. It's easy to get lots of packages to be updated after Portage tree sync, I was kind of tired of that, therefore I started to remove them from package.keyword. If you like newest stuff, go ahead, just be sure you read all messages. I didn't meet any problems after I successfully merged them. It's more common that you see error messages when merge unstable packages than stable packages, but since they are not merged, you are safe.
Don't forget to subscribe to Gentoo Linux Security Advisories, you can also see them at Latest Site News section on front page of Gentoo Forums. If I recall correctly, they are published only after there is a fix or a new version which is immune to threat is available. When you see them in your installed packages list, do the update.
I also set up a code in Conky, so I would know when to do update or how long it's been overdue:
The screenshot above used my new code requiring td.sh, here is an old post about my old code.
Lastly, this is just my way to do update, it might not be suitable to you.