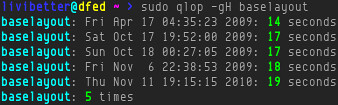
When I was browsing on commandlinefu.com, I saw this entry Block the 6700 worst spamhosts: (URL edited for plain text file)
As of writing (2012-03-24T08:01:18Z), the list, made by Dan Pollock, has grown to 9,502 domains. That is insane! See how many spam websites we have, although not all are spams, some of the entries are legitimate advertising distributors.
To be honest, I was really tempted to use it, but the huge amount of entries did hold me back completely.
If you want to try it, I can propose you a short script as system cron task. I didn't test and I am writing in on the fly, so use it as your own risk:
Be sure to read the comments on the website, which also provides some different modifications and even a RSS feed for notification.
wget -q -O - http://someonewhocares.org/hosts/hosts | grep ^127 >> /etc/hostsAs of writing (2012-03-24T08:01:18Z), the list, made by Dan Pollock, has grown to 9,502 domains. That is insane! See how many spam websites we have, although not all are spams, some of the entries are legitimate advertising distributors.
To be honest, I was really tempted to use it, but the huge amount of entries did hold me back completely.
If you want to try it, I can propose you a short script as system cron task. I didn't test and I am writing in on the fly, so use it as your own risk:
cd /etc
# just in case, you haven't saved current hosts as hosts.local
[[ ! -f hosts.local ]] && exit 1
if [[ "$(curl http://someonewhocares.org/hosts/hosts -z hosts.hosts -o hosts.hosts -s -L -w %{http_code})" == "200" ]]; then
cat hosts.local hosts.hosts > hosts
ficp /etc/hosts{,.local}Be sure to read the comments on the website, which also provides some different modifications and even a RSS feed for notification.