This post was imported from my old blog “Tux Wears Fedora” on 2010-09-28. Some stuff in this post may be broken, please leave a comment if you see any, then I will try to fix it.
If you have heard of or have used
GNU/Screen, then you know what
tmux is for; if you haven't, you probably do not want to read the following content, or you have wasted lots of time in doing terminal window cycling.
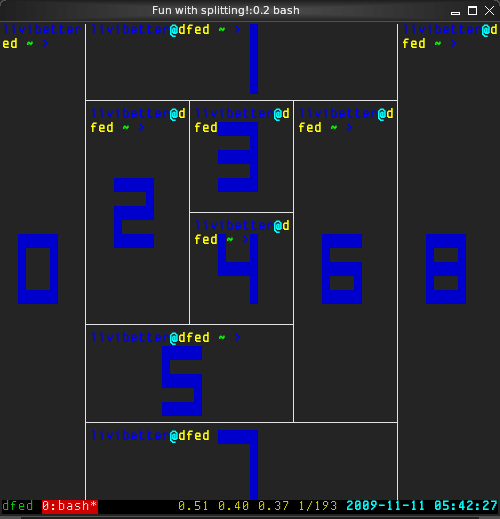
What's the major difference between these two? The splitting:
The numbers in blue indicate the pane number
(Default key: Ctrl+b q)
That maybe over-splitting. Anyway, it's the main reason that I decided to switch to tmux. I know somewhere on the internet has patch for Screen. But I didn't manually compile program, it would be not easy for me to maintain. If you have a good alternative, why bother to keep to the one lacking the functionality which you need. And Screen is no longer to add new feature, it's in bugfix-only. tmux is new, highly active.
tmux's current version is 1.1. I had encounter a problem with version 1.0 when with 256 colors. Some color escape code doesn't do what it suppose to do.
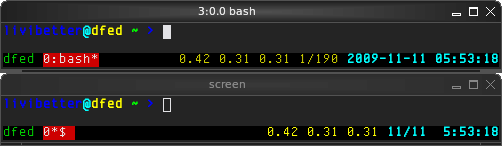
It only took me an hour to create my own configuration to get similar key bindings and status bar.
The one on top is tmux. They are nearly identical and tmux is actually better.
The memory footprint is much smaller than Screen if you usually use several sessions. On my Gentoo amd64, when you start a tmux server, it takes 2.35 MB without counting Bash's; Screen takes 2.6 MB. If you fire up a second session, tmux use 1.0 MB more but Screen uses another 2.6 MB.
My configuraion ~/.tmux.conf
# Last modified: 2009-11-12T05:59:41+0800
# Change prefix key to Ctrl+a
unbind C-b
set -g prefix C-a
# Last active window
unbind l
bind C-a last-window
# Copy mode
unbind [
bind Escape copy-mode
# Use Vi mode
setw -g mode-keys vi
# Make mouse useful in copy mode
setw -g mode-mouse on
# More straight forward key bindings for splitting
unbind %
bind | split-window -h
bind h split-window -h
unbind '"'
bind - split-window -v
bind v split-window -v
# History
set -g history-limit 1000
# Pane
unbind o
bind C-s down-pane
# Terminal emulator window title
set -g set-titles on
set -g set-titles-string '#S:#I.#P #W'
# Status Bar
set -g status-bg black
set -g status-fg white
set -g status-interval 1
set -g status-left '#[fg=green]#H#[default]'
set -g status-right '#[fg=yellow]#(cut -d " " -f 1-4 /proc/loadavg)#[default] #[fg=cyan,bold]%Y-%m-%d %H:%M:%S#[default]'
# Notifying if other windows has activities
setw -g monitor-activity on
set -g visual-activity on
# Highlighting the active window in status bar
setw -g window-status-current-bg red
# Clock
setw -g clock-mode-colour green
setw -g clock-mode-style 24
There is really no much need to explain. The first thing I did was to change the prefix key to
C-a,
C-b is really hard to press.
The other thing I like is you can specify the terminal window's title with the format you like.
Panes Splitting, cycling, etc
Basically, you only need to know four keys for controlling:
Key Default Action
h,| % Split window horizontally
v,- " Split window vertically
C-s o Go to next pane
x x Kill the active pane
q q Show pane numbers
A-Arrow Key Resize the active pane
C-Arrow Key Resize the active pane by one line or on character
I think
h,
v are more straight forward in thinking then
%,
", and
|,
- are more clear but it's harder to press because you have to use Shift key for
|.
C-s is better than
o, it would be even better if you use
C-a as prefix key. You can press in this sequence:
C-a (still hold
Ctrl)
s. A key is next to S, it's much easier to go next pane.
One thing I am not satisfied with panes is it's not easy to know which pane is active if you do not pay attention and the programs do not have blinking cursor. I have the terminal title to indicate the active pane number, so I am able to tell which pane I am in.
Scripting
Sometimes you will want to have presetting windows to be prepared automatically. For example, you may want to have foo program in window 0, window 1 has two split panes, and have bar program in pane 1. Because tmux is highly script-able.
I was actually hoping to use alternative configuration using
-f argument when fire up tmux, but I didn't get it well after some time point. I don't why it didn't seem to work.
Anyway, if you create a script, there is no problem at all.
Here is an example of how I bring up centerim:
#!/bin/sh
tmux new-session -d -s centerim centerim
tmux new-window -t centerim:1 CIM_status_setter.py
tmux select-window -t centerim:0
tmux -2 attach-session -t centerim
The first command creates a detached (
-d) new session named (
-s) centerim and also run centerim in the first window of this new session. It then creates a new window and assigns (
-t) to session centerim's window 1, and also run a Python script. The third one selects the window 0 as the active window.
The last one attaches to session centerim, from here, we would be using this session centerim. The
-2 forces tmux to use 256 colors.
Note that if you need to run a program with arguments, you will need to use quotes, for example:
tmux new-session -d -s session_name 'program arg1 arg2'
Vim
After I switched to tmux, I found out the mouse support in Vim didn't work. My original setting for mouse is:
set mouse=a
set ttymouse=xterm2
Now I have to use:
set mouse=a
set ttymouse=xterm
I still can move the cursor using mouse but the visual selection is different than when
ttymouse=xterm2.
xterm2 Works like "xterm", but with the xterm reporting the
mouse position while the mouse is dragged. This works
much faster and more precise.
Hardcopy and Logging
Currently I don't see tmux has both. In Screen, you can use them by press
C-a h and
C-a H, respectively.
A related operation is to use copy mode, manually select the area, copy to buffer, then use
save-buffer command to save to file.
Clock
You can show the current time in active pane, default key is
t.
The only customization of this clock mode is the color, not really useful feature for me.
Other keys
I think the following keys are most useful for me:
Key Default Action
C-a l Last active window
Escape [ Enter copy-mode
PageUp PageUp Same as above
: : Enter command
? ? Show keybindings
s s Choose session to attach
d d Detach from current session
Conclusion
tmux is easy to learn, you only need the manual of it. The man page is written clear and very useful. Only few things that I could not have tmux to do for me as I had in Screen. I have been using tmux for days, I really don't have a big problem with it. I may uninstall Screen very soon.