I was reading UTF-8 and Unicode FAQ for Unix/Linux, I found many links are dead. Thats the beginning of why I wrote this scrip, linkckr.sh.
Give it a filename or a URL:
./linkckr.sh test.html ./linkckr.sh http://example.com
It does rest for you. You might want to tee, because there is no user interface, it prints results. If a page has many links, you may flood the scrollback buffer. The script is simple, actually, it does too much for me. (Ha, who needs coloring.)
I dont grep the links from HTML source, there always is a missing point in regular expression or the regular expression looks like Hulk. I decided to see if I could use xmllint to get valid links. It means only from normal <a/>, not those hidden somewhere or using JavaScript to open, nor URLs in HTML when you read it plainly with interpreting as HTML. It only takes /HTTPS?/ URLs to check.
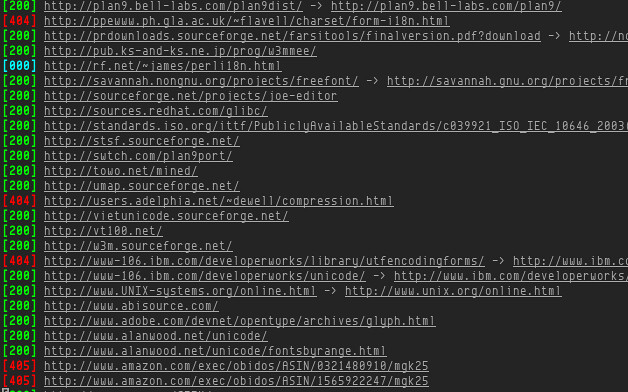
The checking is using cURL and only used HEAD request, so you might get 405 and this script does not re-check with normal GET request. Also, those return 000, which might mean timeout after 10 seconds waiting for response. If a URL is redirected with 3xx, then cURL is instructed to follow up, and the last URL is shown to you.
There are few interesting points while I wrote this script. Firstly, I learned xmllint can select nodes with XPath:
xmllint --shell --html "$1" <<<"cat //a[starts-with(href,'http')]"
And standard input will be seen as command input in xmllints shell.
Secondly, cURL supports output format using -w:
curl -s -I -L -m 10 -w '%{http_code} %{url_effective}\n' "$url"
Note that even you specify a format, the headers of requests are still printed out. The output with the format is appended at last. The script retrieves the last line using sed '$q;d', if you are not familiar with such syntax, you should learn it. sed is quite interesting. Then it parses with built-in read, another interesting I have learned by myself long ago. Using cut is not necessary and its not so good, though read would have problem with additional spaces if those have significant meaning.
The rest is boring Bash. There is a bug I have noticed, the HTML entity in link, that would cause issue.
0 comments:
Post a Comment