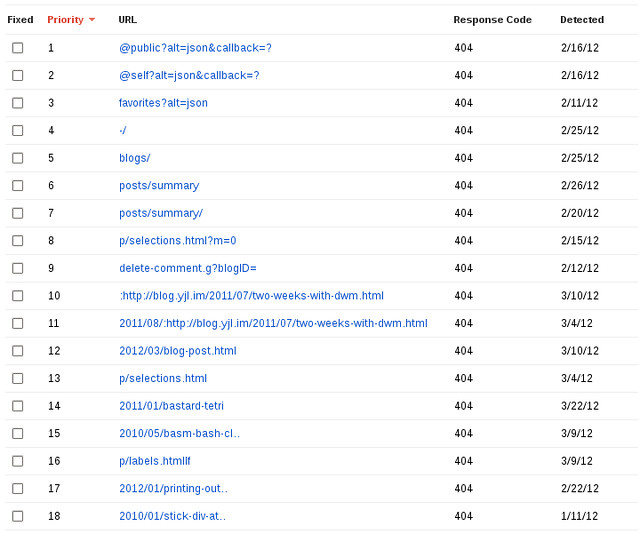
If you are a user of Pentadactyl, you might have noticed whenever you press y on a video of YouTube, you always gets the shortlink. It's been a few months since I first noticed this nice feature.
Recently, I wanted to learn about it, before I dug into codes to find out this fantastic feature is from, I always assumed that's somehow YouTube's effort. I thought there must be some way to intercept URL copying in address bar. Some hook, I supposed. But I was wrong totally, however, gladly, I didn't dive into those minified JavaScript codes.
I first discovered YouTube have a shortlink relation in its HTML,
It is all clear to me now. By default,
Recently, I wanted to learn about it, before I dug into codes to find out this fantastic feature is from, I always assumed that's somehow YouTube's effort. I thought there must be some way to intercept URL copying in address bar. Some hook, I supposed. But I was wrong totally, however, gladly, I didn't dive into those minified JavaScript codes.
I first discovered YouTube have a shortlink relation in its HTML,
<link rel="shortlink" href="http://example.com/promo">Added 'yankshort' option. [b8]
It is all clear to me now. By default,
:set yankshort --- Options --- yankshort=youtube.com,bugzilla.mozilla.orgThere seems no options to disable shortlink yanking unless you remove the site from
yankshort option, if you really need the full URL and don't want to copy from address bar or statueline. A quick resolution is to map a new key to yank full URL:map Y :yank gBrowser.contentDocument.location.href<CR>I really have no idea why I thought YouTube did that. Anyway, I think browsers should provide a link copying button or menu item with shortlink as an option, I saw none in Firefox. I guess this is the reason that YouTube provides shortened link option in share panel.